从脚踏两条船(GOOG TPU和NVDA GPU)的Meta来理解NVDA的护城河
比喻:有伴侣之后又爱上另一个人,那么第二个才是真爱,不然你不会心动,老黄又不是第一天出现在硅谷!
可以不投资M7任何一家大厂,但是不能不知道他们在做什么、底层逻辑和AI发展趋势——模型从训练到推理到Agentic AI协作硬件瓶颈和需求在哪里?
可以不投资NVDA,但是不能不懂NVDA的护城河——AI发展瓶颈从单一芯片算力向大规模GPU之间高效通讯的转移,从底层硬件、连接层、软件生态、供应链掌控,谁才是卡住AI喉咙的王者?
0.Meta兜兜转转又回到NVDA怀抱
先从数字解析为什么Meta收购Manus马上又投向NVDA投怀送抱,如果Agentic AI和推理模型仅仅是最求成本最优,GOOG TPU够好应该继续买TPU,如今为何又多此一举和NVDA联姻?
2025 Aug & Nov:Meta & GOOG $10bn由租转买
2025 Dec:Meta / Manus $2.5bn
2026 Feb:Meta & NVDA $50bn
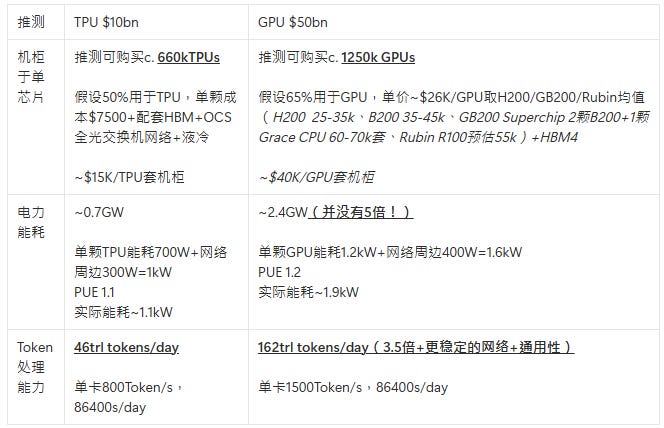
观察一:尽管GPU PUE略逊一筹,5倍的价格但综合电力消耗并没有5倍!美国的AI发展瓶颈在于电!在于电!在于电!
浅浅解析一下GPU PUE受限于物理极限与通用性的妥协:
热密度过高导致热交换损耗:GB200 NVL72机柜总功率高达120kW,这是极其恐怖的热密度。热量必须经过冷板(微通道)>>柜内分水排(Manifold) >>柜内冷却分配单元(CDU)>>数据中心主水管>>室外干冷器。每一次热交换都会损失能量
供电网络(PDN)的热损耗: 要给单颗1200W的GPU稳定供电,电流极其巨大,铜线和电源模块在传输这种极限大电流时,本身就会因为电阻产生大量废热,这部分废热也需要额外的空调去冷却
封闭系统 vs 开放生态: GOOG数据中心从建筑图纸、水管走向到芯片架构,100%封闭定制的,剥离了所有不必要的冗余。而NVDA的系统需要卖给 Meta、MSFT等不同客户,必须保留一定的物理通用接口和电源冗余,这在客观上拉低了极限散热效率
观察二:价格5倍数 vs NVDA deal token产能倍数才~3.5 倍
从数字和财务角度看买NVDA产出Token的性价比(Token per Dollar)似乎低于 TPU,为什么还要买GPU?
这印证了GPU的容错率与稳定性,在Agentic AI时代的护城河被进一步加固——单纯拼单位美元能买到的Token数量,NVDA性价比不如TPU。核心溢价在于网络更稳定、系统更全能,是Agent的最优解
容错率与确定性: NVLink提供的机柜级共享内存,让几十张 GPU 宛如一个单一大脑。在处理Agent需要的海量上下文(KV Cache)和频繁并行计算时,这种无损通讯能保证系统不卡顿、不报错。这就解释了虽然多花了钱,产出的 Token 比例还变少了,但却能获得更稳定更精准的输出
处理复杂动态逻辑: Agent需要不断思考、上网、调用工具、发现错误、退回重试。这种频繁拐弯的动态任务,会把只能跑相对单一场景/直线流水线的TPU跑崩溃。只有NVDA这种灵活的GPU架构,加上强悍的CPU统筹调度,才能稳定接住这些极其复杂的高智商Token
NVDA的护城河——底层硬件+连接层+存储效率与能耗+软件生态+供应链安全(先进制程与存储)+生态布局(电力能源基建、大模型、私域数据、neocloud)
I. 底层硬件(CPU、GPU)完美贴合模型需求
A. 模型迭代:训练>>推理>>代理协作
阶段一:训练——NVDA的暴力美学
基础大模型需要海量矩阵和极致互联同步运算。NVDA凭借强大的Tensor Core+NVLink/InfiniBand+CUDA生态垄断
阶段二:推理——护城河裂痕
模型训练(读完整个图书馆找规律)vs 推理(根据规律回答某个问题)
Regular LLM vs Reasoning LLM推理模型的差异:OpenAI o1或DeepSeek-R1属于Reasoning LLM,这类模型的出现彻底颠覆了硬件需求基于运作机制的本质区别:
Regular LLM (如 GPT-4)采用系统一思考、概率预测predict next token,即用戶输入问题,它凭直觉一次性输出答案 vs
Reasoning LLM (如 o1)则采用系统二思考,在给出最终答案前,它会先在内部生成大量的隐藏思考Token(Hidden CoT),进行树状搜寻(MCTS)、自我反思、错误修正,最终才输出结果
GPU+NVLink/InfiniBand统治模型训练,到了推理阶段成本控制至关重要,因此出现了OpenAI+AMD+AVGO+Cerebras的格局,AMD大容量内存抢夺份额、Groq/Cerebras把内存SRAM做进芯片、云厂商自研芯片瓜分蛋糕,这些护城河裂痕主要基于模型对硬件资源需求变化:
Memory需求激增:推理模型在思考过程中会产生海量内部上下文Context(KV Cache),需要极大的GPU VRAM来存放这些暂时思考的过程(现实情况却是HBM贵的要死、产能瓶颈几家大厂又联合起来加价不拓产,导致NAND HDD都跟着铁树开花)
GPU算力Compute/TFLOPS从受限记忆体频宽变成受限于算力:传统推理瓶颈是把数据从memory搬到运算核心 vs reasoning模型生成答案前要在内部先进行逻辑计算和生成,GPU的浮点运算单元Tensor Cores会被完全榨干,这意味着推理端也需要训练端一样强大的算力
CPU需求:Reasoning模型需要进行复杂的任务调度、强化学习环境、奖励评估以及树状逻辑的路由规划,这些高度串联逻辑判断工作必须依赖CPU(如 NVDA的Grace CPU)来辅助GPU
阶段三:Agentic AI与模型协作——护城河加固
就在市场以为推理市场将被廉价ASIC和AMD瓜分时,Agentic AI的爆发再次掀翻了牌桌——Agentic AI不单具备系统二思考System 2 Thinking能力,给出答案前自己写代码、调用工具、进行多步逻辑推理和自我纠错。常规推理曾让大家以为AI芯片可以变成便宜的单件商品,但Agentic AI告诉世界未来的AI是极其复杂的系统工程。NVDA已经不再卖单一的显卡了,它卖的是能跑Agent的整座AI工厂。这种从卖零件到卖系统的降维打击,让NVDA的护城河在Agent时代不仅没有被撼动,反而被浇筑成了坚不可摧的钢筋混凝土。这种转变让硬件需求发生了四维度的超级膨胀,完美契合了NVDA的战略布局并加深护城河:
算力需求的回城:从“内存受限”重回“算力受限 (Compute Bound)” 常规推理吐出一个字只算一次;但 Reasoning模型在输出第一个字之前,会在内部疯狂生成成千上万个隐藏的思考 Token和CoT思维链。推理阶段的计算量呈指数级暴增,推理变成了小型的训练。结果: 那些专门为“低算力、高并发”设计的廉价推理 ASIC 芯片瞬间算力不够用了,市场再次需要 NVIDIA GPU 那种纯粹的暴力算力(TFLOPS)
显存容量的深渊:KV Cache 爆炸:Agent在思考时,需要把之前的思考步骤、调用的外部网页数据、复杂的上下文全部暂存在内存里(KV Cache)。结果: 显存容量需求极速膨胀。单卡根本装不下,必须多张卡甚至多个机柜联合推理。这时候,NVIDIA的NVLink 网络互连技术再次成为刚需,护城河重新合拢
调度与逻辑的暴增:CPU重新成为主角。这是最核心的剧变。Agent需要做复杂的逻辑判断:“如果这个工具调用失败,我该换哪条路走?”“我需要在这个搜索结果的树状图中找到最优解(MCTS Monte Carlo Tree Search蒙特卡洛树搜索)”*这些高度串行的逻辑判断、工具调用和任务路由,GPU 极不擅长,必须依赖极其强大的 CPU
基础设施的整体联动:Agent不仅要思考,还要频繁与外界交互(调取数据库、上网搜索、操作软件),这要求整个数据中心的网络 I/O 极度通畅
Agent对硬件的苛刻需求(极高算力 + 极大显存 + 极强网络 + 极其聪明的 CPU 调度)完美契合了GB200(将CPU和GPU焊死在一起),以及未来的 Vera Rubin(GPU + CPU + DPU + 交换机六位一体系统级设计)
ASIC(如 Groq、云大厂自研):它们只有加速器,面对 Agent 复杂的 CPU 逻辑调度和跨节点通信,会显得力不从心
AMD:虽然 GPU 内存大,但在 CPU-GPU 深度协同(NVIDIA 有 Grace CPU 专属总线)、机柜级网络交换、以及支持复杂多智能体协同的底层软件库上,仍有巨大代差
Reasoning:内省模式。面对复杂问题在内部生成庞大的“思维树(MCTS)”和隐藏的思维链。它在脑海里疯狂地推演、自我纠错、打分,直到得出结论。硬件需求:GPU 算力榨干 (Compute Bound): 内部成千上万次的路径推演,全是高强度的矩阵乘法,极度依赖 GPU 的 Tensor Core 算力。显存容量深渊 (VRAM/KV Cache): 推演过程中产生的所有废案、假设和中间步骤,都必须暂存在显存(KV Cache)里,这会导致单卡显存瞬间爆满
Agentic AI:外向式。智能体需要将大任务拆解,然后向外调用工具。比如:写一段代码>>丢进编译器跑一下>>报错了>>去网上搜索报错信息>>提取网页内容>>修改代码。硬件需求痛点(除了显存大,还多了两个核心痛点): CPU的绝对重载: 复杂的任务路由Routing、条件判断(If-Else分支)、外部 API的调用与结果解析,这些是高度串行的逻辑工作。GPU/ASIC面对这种工作极其笨拙,必须依赖性能极强的 CPU 来作为“大脑总指挥”。极高的网络 I/O要求: Agent需要频繁与外部数据库、互联网、其他软件甚至其他 Agent 进行数据交换,整个数据中心的网络进出必须毫无阻塞
B. NVDA伴随模型迭代
Hopper(2022-2023):H100奠定了生成式AI如ChatGPT的爆发基础。H200核心算力没变,患上了HBM3e,专门解决大模型推理脑容量不够用的问题
Blackwell(2024-2025):B100/B200单块硅偏面积达到了物理极限,NVDA第一次采用拼接技术把两块芯片像三明治一样拼起来,算力比H100翻了数倍。GB200把2块B200和一块Grace CPU焊在一个板上,标志着NVDA从卖显卡向卖系统转变
Rubin(2026+):R100/R200预计2026量产,采用HBM4内存,引入六位一体的系统协同设计(GPU+CPU+DPU+NVLink交换机+网卡+以太交换机等)与液冷生态
CPU Grace:初衷并非要去通用x86(INTC/AMD)市场竞争,而是为了解决数据传输瓶颈。Grace-Hopper/Grace-Blackwell将Grace CPU和GPU封装在一起,实现了统一记忆(Memory Coherency),CPU和GPU可以直接共享一块memory,频宽高达900GB/s
C. 模型算力利用率MFU(Model FLOPs Utilization)鬼故事
一块标称算力1000 TFLOPS的显卡在实际训练大模型时,通常只能发挥40~60%的理论性能,这并不是 NVIDIA 虚假宣传,而是受制于物理规律
内存墙Memory Wall:显卡算太快了,但把数据从内存HBM搬到计算核心Tensor Core的速度跟不上。就像一个天才数学家GPU一秒钟就能算完一页纸,但旁边递纸的助手(内存带宽)要等 3 秒钟才能递过来下一页。这 3 秒钟,数学家只能坐着发呆(算力闲置) → 把HBM显存和芯片封装在一起,缩短物理距离
通讯墙Communication Wall:训练大模型需要上万张卡协同。这张卡算完一部分,得等另一张卡的结果传过来才能继续。网络只要有一点延迟,所有卡都要停下来等 →NVLink
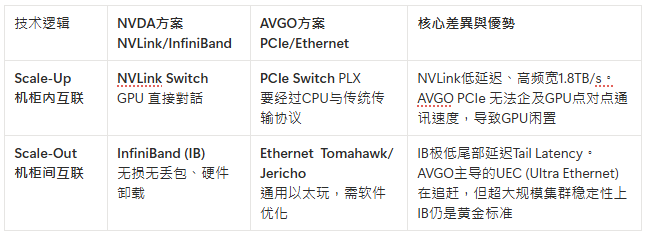
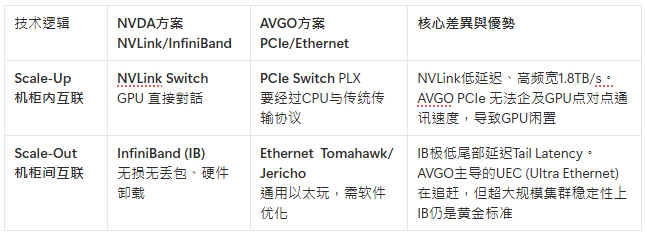
II. 链接层NVLink/ InfiniBand vs UALink (Ultra Accelerator Link):
两套GPU集成哲学形成的双壁垒
Scaling Up: Increase server Capacity 将8个独立GPU统一成一个超级GPU超级节点Supernode,让每个GPU协同思考,成功关键在于每个GPU能直接读写另一个GPU的记忆体(Memory Semantics记忆体语义)
Scaling Out: Add additional servers 将成百上千个服务器透过通讯网络Ethernet or InfiniBand连接起来
通讯方式:PCle vs NVLink vs InifiniBand
从Hopper架构(2022)单脑冠军>> Blackwell架构(2024)双脑设计>> Rubin架构(2026)多脑协同,展现了NVDA的技术路线把大脑和通讯网络同步进化的策略
PCIe(Peripheral Component Interconnect Express):类似高速公路,服务于所有人——显卡、网卡、硬盘,所有设备数据都在上面跑。数据路径GPU1 >> CPU >> GPU2,CPU这个中转站成为瓶颈。哪怕是最先进的PCle5.0 128GB/s的双向频宽也是GPU工作的短板
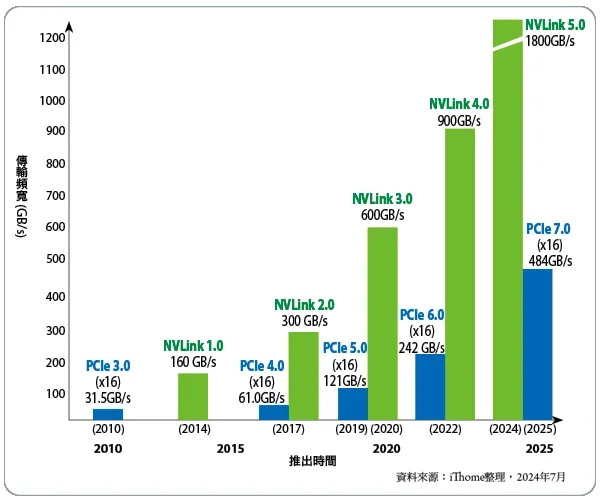
NVLink:NVDA为自己GPU修建的专属超级高速,实现数据在GPU1<>GPU2心电感应般传输。Hopper架构下的NVLink4.0提供了900GB/s频宽,是PCle5.0的7x;到了NVLink5.0快了14x,这简直是F1赛车和自行车的区别!同时解决了传统Ethernet丢包的问题
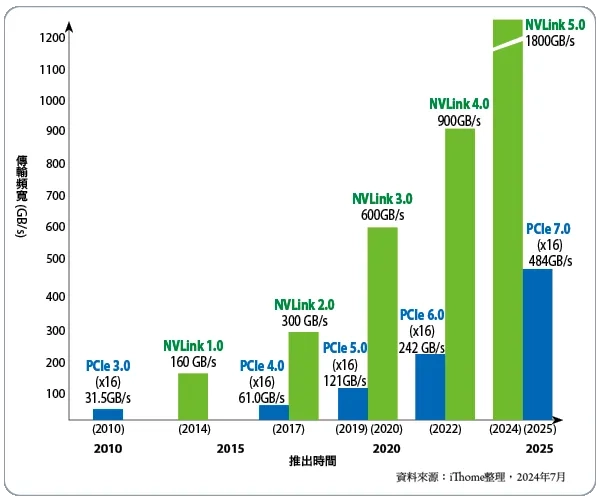
InfiniBand:
如果说NVLink实现了GPU大脑的高速连接(Scale Up),那么InfiniBand让上千个这样的超级节点进行心电感应般交流(Scale Out)
RDMA远端直接记忆体存取是InfiniBand最精妙之处。传统以太网络通讯GPU之间通讯需要通过CPU来传话,而InfiniBand的RDMA技术允许GPU直接读取另一台远在天边GPU的memory
这并不是NVDA的秘密武器,而是一个由行业协会InifiniBand Trade Association维护的开放标准,NVDA通过2019年Mellanox完成这一块拼图
IB 的无损机制:IB 网络就像发“通行证”,接收方明确表示“我有空位”,发送方才会发数据(Credit-based flow control),所以物理上零丢包
Spectrum-X 的诞生:NVDA 极其聪明,黄仁勋的策略是“走别人的路,让别人无路可走”。NVDA 推出了 Spectrum-X(专门针对 AI 优化过的以太网交换机),对云厂商说:“你们如果嫌 IB 贵,或者因为历史原因非要用以太网,没关系,我这里也有全世界最强的 AI 以太网设备,你们还是得买我的”
UALink (Ultra Accelerator Link):
AMD、INTC、GOOG、META、MSFT、AVGO联合推动的反NVDA联盟,为了解决非NVDA阵营开发者要写不同的语言(PyTorch、TensorFlow)
然而UALink距离NVLink至少还有2-3年的代差(UALink 1.0标准基于PCle6.0刚刚制定,硬件落地要到2026年甚至更晚)。UALink的出现仅仅是为了制衡NVDA,性能、稳定度、生态整合远远不及NVDA
UALink虽是开放标准,联盟内部各怀鬼胎(比如INTC有自己的标准、AMD也有),当不同厂商的芯片用UALink连起来后,软件层面出了bug谁负责?
AVGO无法撼动的NVDA护城河
III. 存储效率与能耗
存储:与HBM厂商深度绑定:透过CoWoS封装,将HBM与GPU裸晶紧密结合,极大优化memory频宽降低传输能耗
液冷:供电网络PDN与液冷,NVDA直接参与机柜铜线背板涉及,提高了能效比PUE
旧方法:风冷+冰水主机。就像在机房里有一台巨型冷气,耗费大量电力制造7~15°C 冷水+吹冷风带走热量。痛点:空气导热差,来不及带走热量,占了30-40%电力资源
NVDA逻辑:DLC(Direct Liquid Cooling)精准吸热。水导热是空气25倍以上,直接在芯片表面贴上金属冷板Cold-Plate把热量带走
举例而言,Vera Rubin 2300W的功耗全速运转时温度达到80~90°C,只需要45°C水就能带走热量,而不需要15°C再吹风;带着芯片热量的高温水(比如60°C)流到室外与空气30~35°C自然交换即可降温再次循环使用,剩下散热电费
微通道冷板Micro-Channel Cold Plates:NVDA在芯片上设计封装阶段已纳入考量,在冷板内部设计了微米级流道,让冷却液能无线逼近芯片发热的核心区
IV. 软件生态CUDA
全球所有的AI模型几乎都是用PyThorch/TensorFlow这两个框架写的,这两个架构底层就是CUDA,拥有4mm开发者的肌肉记忆。CUDA旗下的cuDNN、TensorRT、NCCL无数针对深度学习底层优化的函数库,全球所有AI开发者、论文、开源模型都基于CUDA撰写
为什么 ROCm无法超越 CUDA?(护城河有多深)
AMD的ROCm努力相容,当永远在追赶,Edge cases(边缘案例)容易崩溃,因此买AMD的芯片剩下来的钱会赔在软件纠错的人力成本上(翻译永远比不上原生,总有不可预期的bug;没人敢冒险去学一个市占率极低且容易出错的新语言)
能跑和跑得好是天壤之别(底层优化的代差):NVDA花了15年,培养了成千上万个博士,把数学、物理、化学、AI最底层算法,全部写成了几百个极其优化的“现成函式库Libraries”(如 cuDNN)。AMD的ROCm库数量和深度都不及NVDA的十分之一。这就好比AMD给你提供了一块好木头和锯子,而NVDA直接给你提供了宜家的全套拼装零件
它就是能用的商业黄金法则:企业训练一个大模型动辄花费千万美元。在NVDA平台按下运行键它就能稳定跑完vsAMD平台可能会遇到驱动崩溃、某些奇怪的运算不支持、网络断连。时间就是金钱,企业宁愿花高价买 NVIDIA 的稳定,也不愿让拿着百万年薪的 AI 研究员去帮 AMD 修 Bug
庞大的沉没成本与人才肌肉记忆:全球有数百万工程师是从大学开始就学 CUDA 的,网上的开源代码、遇到Bug时的提问贴StackOverflow全是基于 CUDA 的。要让整个行业的人抛弃一套极其成熟的工具,去学一套尚在完善中的工具,阻力是物理级的
翻译工具的局限性:AMD提供了
HIP工具,号称能把CUDA代码自动翻译成ROCm代码,但在软件工程界自动翻译永远打不过原生开发。翻译过来的代码往往效率低下,且在处理极端复杂的模型时容易报错总结而言,AMD ROCm像一个正在努力补课的优等生**,凭借硬件高性价比和反垄断的情绪会在推理和巨头内部的定制化项目中抢下客观的份额。但是NVDA的CUDA是一套已经运转了15年的成熟基础设施。在需要极致性能、极其复杂的大模型训练以及通用科研/企业市场**中,CUDA的霸主地位依然坚如磐石
V. 供应链安全
制程:NVDA通过巨额预付款锁定了TSMC绝大部分CoWoS产能;通过投资INTC锁定本土供应链安全
光模块:InfiniBand网络,NVDA严格控制规格,并于中际旭创、LITE、COHR深度绑定,确保光电转换良率能配合GPU迭代周期
存储产能预定
VI. 生态布局与侧重
透视整条价值链:
TSMC/SK Hynix(卖螺丝钉螺丝刀) >> NVDA(造收割机) >> Meta/MSFT/Oracle/CRWV(云厂商买收割机自用或者出租)>> OpenAI(租收割机种粮食/罂粟) >>你我(买粮食/白粉吃,目前仍在白嫖)
NVDA 卡在最核心的咽喉,赚取了最高额的垄断利润,远期市盈率Forward P/E在30-40x price in了“算力垄断”、“软件生态税”的溢价,2026年业绩爆炸以及AI算力将成为水电一样的基础设施,风险在于2027/2028年云巨头CapEx潜在断崖式下跌(周期股)和2029年的不确定性(保持高增长+高确定性)
2026年:极大概率维持高增长(确定性极高)。巨头们目前陷入囚徒困境,谁不敢投资算力谁就可能错过AGI,目前2026年订单已经被大厂买断,NVDA的业绩能见度极高
2027 - 2028 年:面临断崖式下跌的危险(ROI 审判日)。**极其关键的分水岭——到了2027年企业依然发现AI只能用来写写邮件、做做总结,而没有产生能填补几千亿美元CapEx的杀手级应用(例如真正完全替代人类程序员、客服中心,或实现 L5 级自动驾驶),华尔街的耐心将耗尽,巨头们将面临股东的逼宫,被迫大幅削减买卡的预算,这时候 CapEx 就会断崖式下跌
2029年之后:范式转移。**Agentic AI爆发,创造了全新的经济增量,那么 CapEx 会转化为稳定的常态化基础设施投资(像今天建数据中心一样)
NVDA阵营
xAI $20bn债务以NVDA芯片为抵押品
Mistral欧洲最强大模型:2025 Nov EUR1.7bn融资,NVDA参与
Oracle
2025 NVDA/OpenAI $100bn: 2026 Feb弃用此前的千亿大单,转而缩水成一份$30bn的股权投资
2025 NVDA+MS/Anthropic $15bn
2026 Meta/NVDA $50bn
BioNeMo生态(NVDA铁杆阵营Eli Lily & RXRX):NVDA将生物制药视为下一个兆元级别应用,向RXRX注资$50mm——RXRX拿资金购买NVDA DGX系統,並使用 NVDA的BioNeMo平台训练AI药物发现模型,LLY也一来这套软硬件生态进行研发
Neocloud:NVDA在Neocloud上的订单确实都变成了真实的显卡出货量,机房里堆满了算力,但这背后隐藏着目前最担忧的泡沫逻辑,Neocloud买卡的钱几乎全是借来的或是 NVDA循环投资的。一旦底层债务市场因为算力无法迅速变现为盈利而拒绝继续放贷(正如目前发生的),这些巨额CapEx承诺可能瞬间变成一地烂尾楼,这也解释了为何NVDA 会在近期开始抛售部分边缘 Neocloud(如 Applied Digital)的股票
CoreWeave:Pre IPO投资$2bn,20261约再次注资$2bn($87.2/s),并承诺2032年前$6bn反向收购云服务。2030年前建成5GW NVDA AI工厂,融资伙伴Blue Owl Capital近期未能为$4bn数据中心筹集足够紫金引发资金链断裂的恐慌
Nebius:定位为欧洲首屈一指的AI工厂,近期财报显示其营收暴增 355%,但亏损急剧扩大,为了填补资金黑洞正试图发行新债并**直接用 GPU 作为抵押品贷款,**受 CRWV拖累其股价也遭遇重挫
Applied Digital:NVDA层持有$169mm,2026年2约清仓,划清与APLD依赖私募信贷市场借钱买卡的界限
IREN:拥有廉价绿电和现成基础设施进行AI算力租赁
非NVDA阵营
2023 MS/OpenAI $13bn(部分NVDA)
2023 GOOG+AMZN/Anthropic $6bn
2025 OpenAI/MS+AMD $250bn
2025 AMZN/OpenAI $10bn
未完全明确阵营
2026 AMZN Capex $200bn
2026 GOOG Capex $175-185bn
2026 MSFT Capex $140bn
2026 Meta Capex $125bn
2026 TSLA Capex $20bn
AAPL/GOOG
中国大厂$53bn百模大战:字节、BABA、Tencent、电信运营商;以及60-70%流向H20,15-20%光模块,其余10-25%数据中心建设液冷等(部分NVDA)
电力能源、私域数据与大模型
电力能源:NVDA没有直接投资盖核电站,但通过与Vertiv、Scheneider等基础设施大厂合作涉及AI专用机房。重资产领域,不碰
大模型与私域数据:维持卖铲人身份,NVDA有自己的大模型,Nemotron为了狗粮先吃Dogfooding,确保硬件设计没有缺陷。另一方面重要,但短期难以变现
为什么不碰电力大模型、私域数据?这是NVDA的聪明之处——不与金主爸爸(云巨头)抢饭碗,不碰重资产(核电/土建),避免了陷入Capex/大模型烧钱大战(MSFT、GOOG、Meta、Nebius、OpenAI等),只做最强卖铲人,维持70%+高毛利
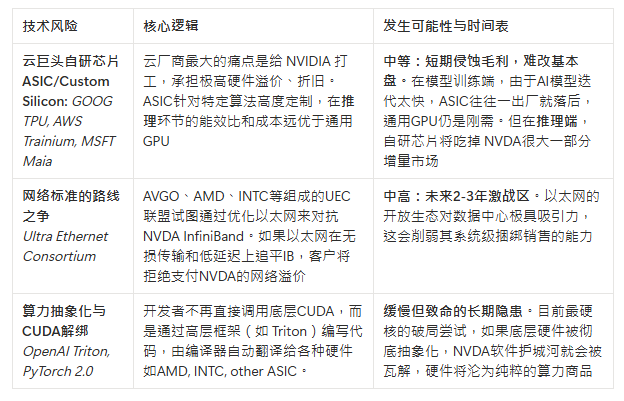
VII. 护城河的潜在撼动者
NVDA的技术护城河由GPU泛用性+InfiniBand网络+CUDA生态构成,而技术风险也正是冲着这三个核心堡垒来的
GPU vs TPU非零和博弈——Agentic AI 的饼未来怎么切?
GOOG闭环帝国:TPU + 谷歌自家的 CPU,关起门来供 Gemini 和GOOG生态使用,外人很难插足。TPU在特定场景成本效率高,但NVDA依然是大赢家,即使市占率、毛利波动,绝对金额尚仍然享有最大增长红利
非GOOG的广阔世界:这里将是 NVDA 的绝对主场。Agentic AI 需要极强的“逻辑路由、工具调用”能力(极度依赖 CPU),以及极大的“共享记忆”(依赖 GPU 之间的 NVLink 互联)。NVDA 顺势推出的 GB200(将自家 Grace CPU 和 GPU 绑死在一起),就是为了吃下市面上绝大多数 Agentic AI 的需求。GPU的通用性:Sovereign AI(如日本、中东)像石油一样的战略物资,他们没有自研芯片能力,只能购买NVDA的生态系统
算力抽象化 vs 高层框架自动翻译Triton:大家不想被CUDA绑定,OpenAI开发了Triton,以后只管写高层代码,Triton能自动把代码盲翻给NVDA的卡也能翻给AMD 的卡,这就叫“硬件被抽象化隐藏了”
2025 GTC大上 500bn确认订单约150bn已经交付,350bn预计2026年底前完成,下周(02/25)财报需要进一步关注交付情况
VIII. 关键财务指标
Commitments & Obligations NVDA向TSMC、MU、SK Hynix等上游供应商下达的不可取消的产能预定订单
客户集中度:数据中心收入有将近一半来自于极少数的几家Hyperscalers,结构非常脆弱,只要其中任何一家(比如META, MSFT, OpenAI)放缓半年的采购节奏以消化库存,NVDA当季财报就会大幅不及预期
Gross Margin:英伟达税算力垄断的体现, 目前高达70%+的毛利率是典型的短缺经济学产物。随着台积电CoWoS拓产、AMD MI300/MI325 系列以高性价比抢占市场,以及云厂商自研芯片的实装,这种超额利润率在未来两三年内几乎必然面临向50%-60%历史均值回归的压力
FCF to Net Income:看花的钱是否转化成利润,或者需要不断举债来填补资本支出,也要关注表外投资
Capex Cliff vs ROI:目前大厂们每年动辄几百亿美元买卡,前提是他们相信这些投入能在未来转化为SaaS订阅、广告增量或云服务收入。如果1-2年后,下游AI应用无法产生匹配的现金流,巨头们将被迫削减 CapEx,NVDA的营收将出现断崖式暴跌
Inventory
Turnover变慢:
空头逻辑:Neocloud面临信用风险,算力卖不掉,NVDA应收回款变成坏账(渠道压货) vs
多头逻辑:NVDA产品一下线就立刻发货,但季度最后2-3周才完成交付确认,潜在拉高DSO。客户从OEM变为hyperscalers & 主权国家,溢价能力强
需求Cliff:
空头逻辑:客户在等下一代Rubin,导致当前Hopper卖不掉了,重蹈2018-2022加密寒冬的覆辙 vs
多头逻辑:暴增的不是finished goods,而是原材料(比如SK Hynix的HBM3e、CoWoS产能)为下一季备粮,而非产品滞销;从卖芯片→卖系统的周期拉长,现在交付的GB200 NVL72机柜集成了36个CPU+72个GPU+NVLink+铜缆+液冷板,生产、测试、交付周期都长于单芯片
其他风险:产能、地缘政治与反垄断
台积电产能瓶颈:TSMC的CoWoS先进封装产能是否能跟上NVDA的订单
中美各自开了绿灯,H200阉割版销售
欧美监管对捆绑销售InfiniBand调查拆分
估值已透支预期